Post Detail Page
OpenAI API를 이용한 ChatBot 구현하기-API 연결하기
🤖 GGF 프로젝트 - 챗봇 만들기
챗봇을 왜 만들어야할까?
1️⃣ 사용자 경험 개선
GGF 웹을 처음 사용하는 사용자들에게 챗봇을 통해 친절하고 직관적인 안내를 제공하여, 서비스 이용에 대한 부담을 줄일 수 있다. 챗봇은 사용자의 초기 접근성을 높여줄 뿐만 아니라, 사용자들이 원하는 정보를 신속하게 얻을 수 있는 효율적인 수단이다.
2️⃣ 편의성 제공
요즘은 일상생활에서도 챗봇이 많이 활용되고 있는데 특히 간단한 내용 작성 및 검색에도 챗봇이 적극적으로 활용되고 있다. 게임 아이디 생성부터 게임 모집 글 작성까지 자동으로 작성해 주는 챗봇을 통해 사용자들에게 편의성을 제공하려고 한다.
🛠️ 기능 고민해 보기
FAQ: 자주 묻는 질문
- GGF란?
- 파티원은 어디서 모집하나요?
- 클랜은 어디서 모집하나요?
- GGF 크리에이터란?
QWER 대화 기능
- 텍스트 기반 상호작용에 익숙한 사용자들에게 간편하고 신속한 질의응답 제공
- 모든 페이지에서 쉽게 접근 가능
🤖 귀여운 QWER 🤖
🤖 챗봇 모델
사용할 모델: gpt-3.5-turbo
- 역할(Role) 기반의 모델입니다.
- 대화형 문제 해결을 위해 훈련된 모델입니다.
- 각각의 개체는 역할(
시스템,사용자, 또는어시스턴트)과 콘텐츠를 포함해야 합니다. - 모델은 입력에 대한 응답으로 텍스트를 생성합니다.
- 모델에 대한 입력을
프롬프트라고 합니다.
💲 토큰 규정 확인하기

✅ 1000토큰에 0.002$
✅ 영문은 보통 단어 하나가 하나의 토큰으로 취급되지만 국문은 글자 하나당 하나의 토큰으로 계산되기 때문에 동일한 작업을 하더라도 영어로 대화하면 토큰을 적게 소모할 가능성이 높다.
✅ 한 요청당 최대 4097 토큰까지 사용 가능하다.
✅ OpenAI가 제공하는 가이드에서 Token과 Token limits를 확인해 보면, 프롬프트와 생성된 출력을 합친 것이 모델의 최대 컨텍스트 길이보다 길면 안 된다.
🔥 토큰 주의사항
내가 입력한 값 + 출력값을 합쳐서 토큰으로 계산되는데 이때,답변뿐만 아니라 질문 포함모든 대화가 누적될 때마다 토큰이 소요되기 때문에 이를 잘 고려해서 텍스트 길이를 정해야한다.
➕➖🟰 토큰 계산해 보기
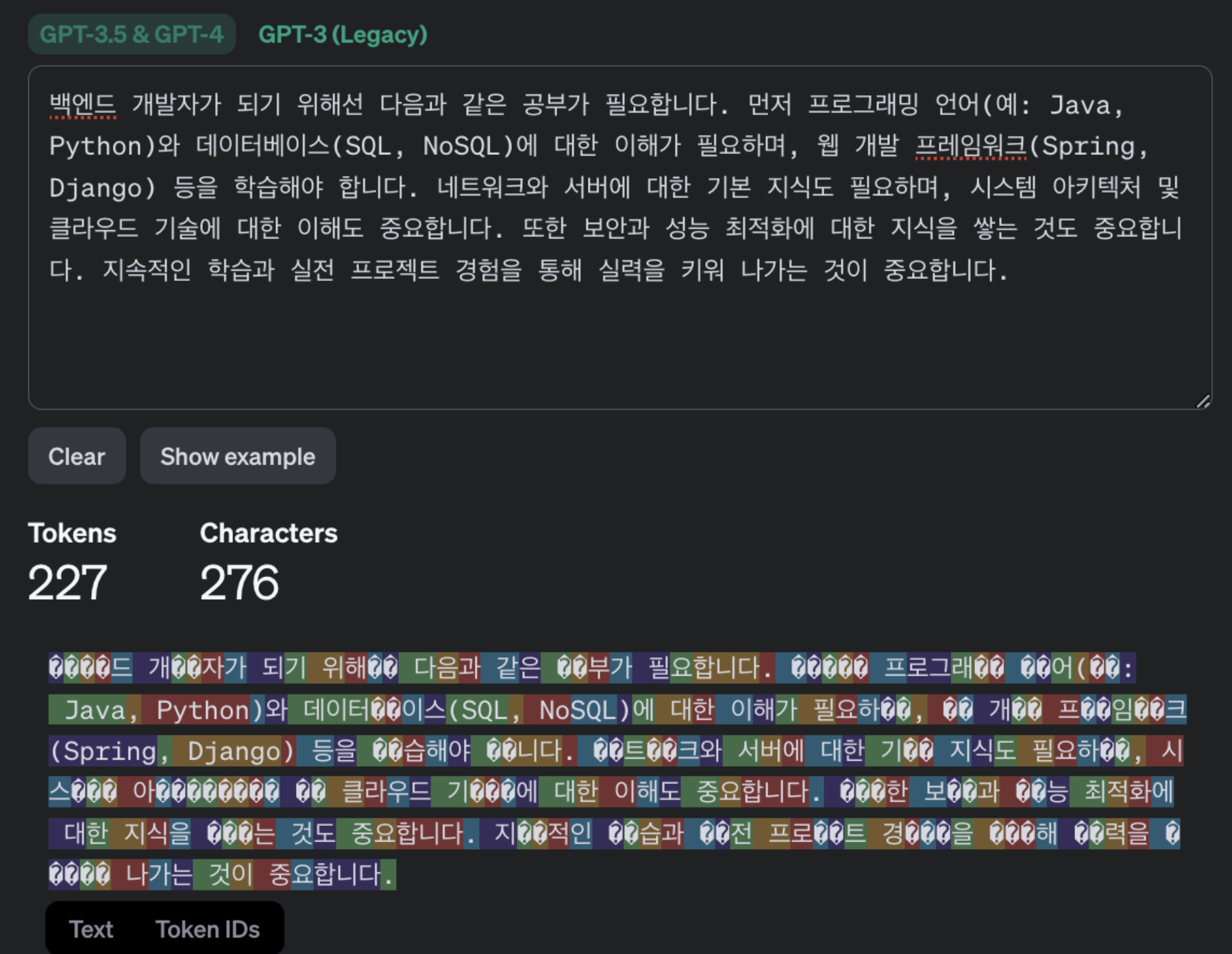
Tokenizer를 사용하면 작성한 문장의 예상 토큰을 알 수 있어서 챗봇의 답변 글자 수를 제한하기 위해 몇 가지 실험해 봤다.
Q. 백엔드 개발자가 되기 위해 어떤 공부를 해야할까?
A. 백엔드 개발자가 되기 위해선 다음과 같은 공부가 필요합니다. 먼저 프로그래밍 언어(예: Java, Python)와 데이터베이스(SQL, NoSQL)에 대한 이해가 필요하며, 웹 개발 프레임워크(Spring, Django) 등을 학습해야 합니다. 네트워크와 서버에 대한 기본 지식도 필요하며, 시스템 아키텍처 및 클라우드 기술에 대한 이해도 중요합니다. 또한 보안과 성능 최적화에 대한 지식을 쌓는 것도 중요합니다. 지속적인 학습과 실전 프로젝트 경험을 통해 실력을 키워 나가는 것이 중요합니다.
🔗 Tokenizer 이용해서 토큰 수 알아보기
⌨️ Prompt 기본 내용 설정하기
/*
GPT Persona (Tokens-184)
- 당신의 이름은 QWER입니다
- QWER은 게임 사이트 챗봇입니다.
- 게임사이트 이름은 GGR입니다.
- 당신은 게임 유저들의 질문에 답변해야 합니다.
- 모든 답변은 대한민국 기준으로 합니다.
- 답변은 200자 내외로 합니다.
- 답변은 문장이 끊어지지 않고 마침표로 문장을 끝내야 합니다.
- 답변은 예의 있고 친근한 말투를 사용합니다.
- 다음 질문에 위의 내용을 반영하여 답변하십시오.
*/
export const PROMPT = `질문에 대한 답은 아래 사항을 모두 읽고 반영해 주세요.
1. 대한민국 기준으로 대답합니다.
2. 답변은 200자 내외로 정리해서 문장이 끊어지지 않고 마침표로 문장으로 끝내야 합니다.
질문: `;
GPT 페르소나를 설정하려고 했지만, 무료 버전 사용자인 나에게는 184개의 토큰이 너무 커서 페르소나를 삭제했다..🥹 모든 프롬프트의 첫 대화에 적용할 경우 엄청난 토큰이 소요된다.
사용자와 챗봇이 최소 5회 이상 대화하고 대화가 연결된 흐름을 가져야 하고 게임 커뮤니티를 자주 사용하는 5명의 사용자를 대상으로 받은 피드백을 반영하여 챗봇 영역을 벗어나는 긴 답변은 가독성이 떨어져 오히려 사용자 경험에 좋지 않을 것 같아 200자 내외로 제한했다.
200자 내외로 지정한다고 해서 끝이 아니었다.. 완벽한 문장으로 끝나야 하는데 중간에 끊겨서 출력되는 문제가 있어 마침표를 통해 문장을 완료해야 한다는 조건을 추가했다.
나만 그런 건지 모르겠는데 한국 기준으로 답변을 안 할 때가 종종 있어서 첫 번째 조건으로 대한민국 기준으로 대답하는 조건을 추가 작성했다.

☻ 총 96토큰으로 프롬프트 설정 완료!
OpenAI 연동 후에 Prompt 상수 파일을 만들어서 사용자 질문 앞에 적용할 예정이다.
📌 OpenAI 설치
npm install openai📌 API 연결하기
📂 디렉터리 구조
GGF
├── src
│ ├── apis
│ │ └── chatbot.ts // Axios를 사용한 API 요청 관련 모듈
│ ├── components
│ │ └── commons
│ │ └── chatbot // 챗봇 관련 컴포넌트 모음
│ │ ├── data-access
│ │ │ └── useRequestAnswer.ts
│ │ ├── ChatbotButton.tsx
│ │ ├── ChatbotDialog.tsx
│ │ ├── ChatHeader.tsx
│ │ ├── DialogCard.tsx
│ │ ├── FAQ.tsx
│ │ ├── FAQChatDialog.tsx
│ │ ├── Loading.tsx
│ │ └── index.ts
│ ├── constants
│ │ └── prompt.ts // 프롬프트 설정 파일
│ └── pages
│ └── api
│ └── generate.ts // API 라우트 설정 파일☹︎ 컴포넌트 역할 분리
이전에는 질문/응답 처리,API 호출, 데이터 가공 로직이 모두 chatbot 컴포넌트 내부에서 처리됐었다.
컴포넌트의 역할이 너무 많아 코드가 복잡해 보인다는 조언을 듣고 로직과 뷰를 분리하는 작업을 했다.
☻ data-access
- 비즈니스 로직에서 필요한 데이터를 처리하는 역할
- 사용자 질문을 API로 전송하고 응답을 받아와서 필요한 형식으로 가공하여 컴포넌트에 제공
📝 generate.ts
🔗 Chat Completions API
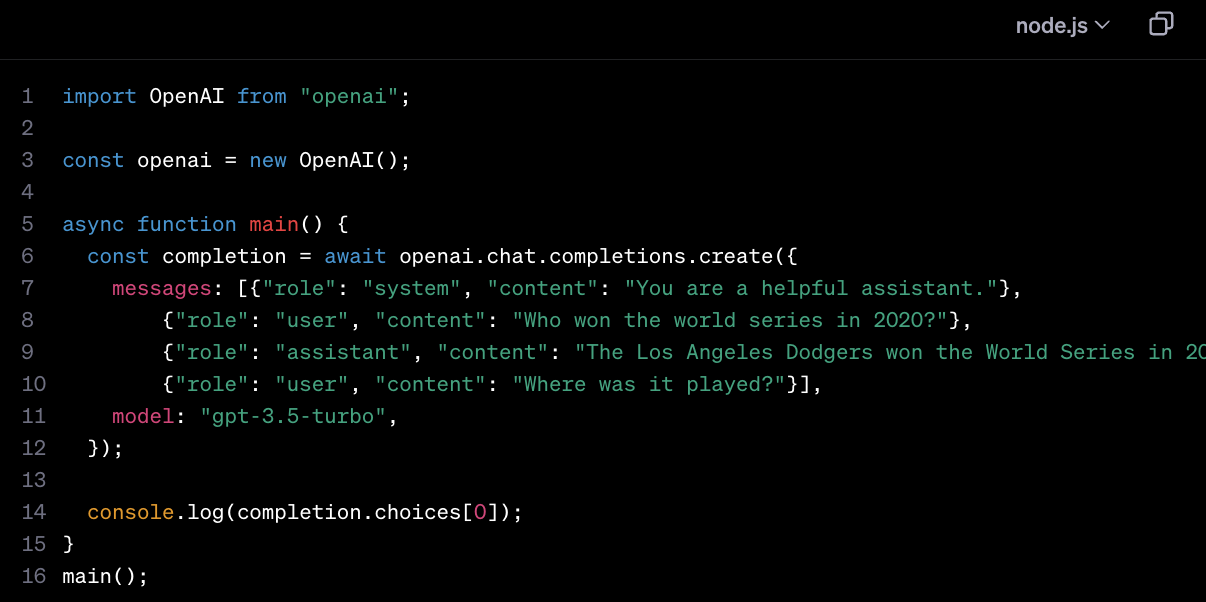
위의 문서를 참고하여 기본 코드를 작성했다.
import { NextApiRequest, NextApiResponse } from 'next';
import { OpenAI } from 'openai';
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
export default async function handler(req: NextApiRequest, res: NextApiResponse) {
const completion = await openai.chat.completions.create({
messages: [
{ role: 'system', content: 'You are a helpful assistant.' },
{ role: 'user', content: 'Who won the world series in 2020?' },
],
model: 'gpt-3.5-turbo',
});
console.log(completion.choices[0]);
}Role 정하기
☻ GGF 서비스로 생각하기
웹 사이트에서시스템(system)은 QWER을 나타내며,사용자(user)는 게이머가 된다.
const completion = await openai.chat.completions.create({
messages: [
{ role: 'system', content: '게임 예약 서비스인 GGF의 챗봇입니다.' },
{ role: 'user', content: 'GGF가 무엇입니까?' },
],
model: 'gpt-3.5-turbo',
});Response 설정하기
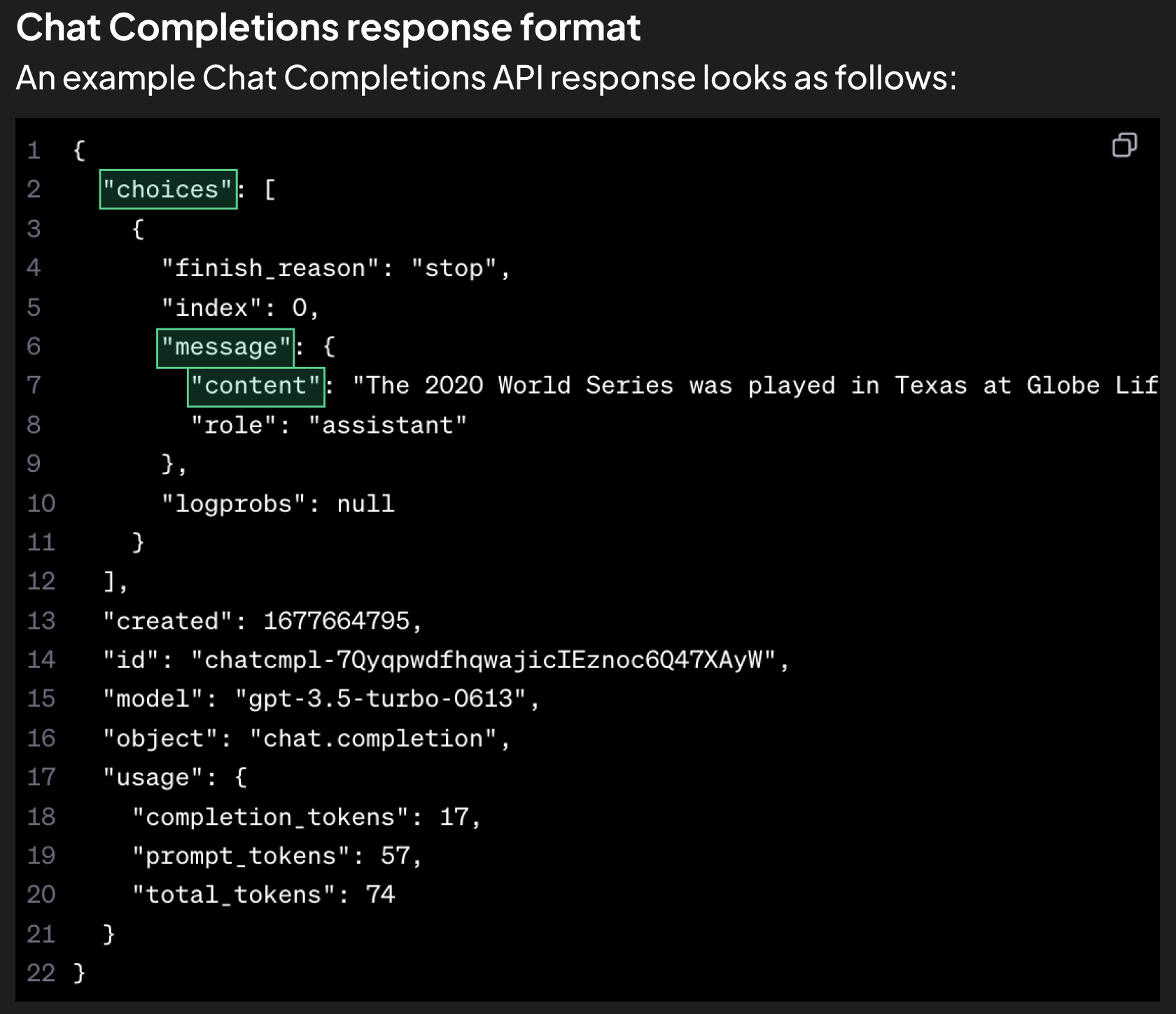
🔗 Chat Completions response
반환되는 JSON은 공식 문서에서 안내하는 아래 이미지와 같이 나온다.
내가 원하는 출력값은 message 안의 content기 때문에 completion.choices[0].message.content값을 반환해 주면 된다.
import { NextApiRequest, NextApiResponse } from 'next';
import * as dotenv from 'dotenv';
import { OpenAI } from 'openai';
import { PROMPT } from '@/constants';
dotenv.config({ path: __dirname + '/.env' });
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
export default async function handler(req: NextApiRequest, res: NextApiResponse) {
try {
const completion = await openai.chat.completions.create({
messages: [
{ role: 'system', content: '게임 예약 서비스인 GGF의 챗봇입니다.' },
{
role: 'user',
content: `${PROMPT} ${req.body.question}`, // 프롬프트 내용 질문 앞에 적용
},
],
model: 'gpt-3.5-turbo',
temperature: 0.5,
max_tokens: 250,
top_p: 1,
});
res.status(200).json({ answer: completion.choices[0].message.content });
} catch (e) {
console.error('OpenAI API ENCOUNTERED AN ERROR: ', e);
res.status(500).json({ error: 'Internal Server Error' });
}
}- model : 사용할 OpenAI 모델
- message : 대화 메시지를 제공하는 배열, 메시지는 role과 content 속성을 가지고 있다.
role: 메시지가 속하는 역할을 지정한다. 'system'은 챗봇 시스템을 나타내고, 'user'는 사용자(=게이머)를 나타낸다.content: 역할에 따른 메시지의 내용을 정의. 사용자의 질문이나 시스템의 응답이 여기에 해당한다.
- temperature : 답변의 다양성을 지정하는 파라미터로 값이 높을수록 생성하는 문장이 다양하고 창의적인 결과물을 만들어 준다. (0.5 - 1.0 사이의 값으로 주로 사용 됨/기본값: 0.7)
- max_token : 생성된 텍스트의 최대 토큰 수를 지정한다 -> 답변 길이 제어
- top_p: 텍스트 생성 시 가능한 다음 단어의 후보를 제어하는 매개변수로, 높은 값은 더 다양한 텍스트를 생성한다. (기본값: 1.0)